The High Cost of Splitting Related Data
Consider the following simple architecture:
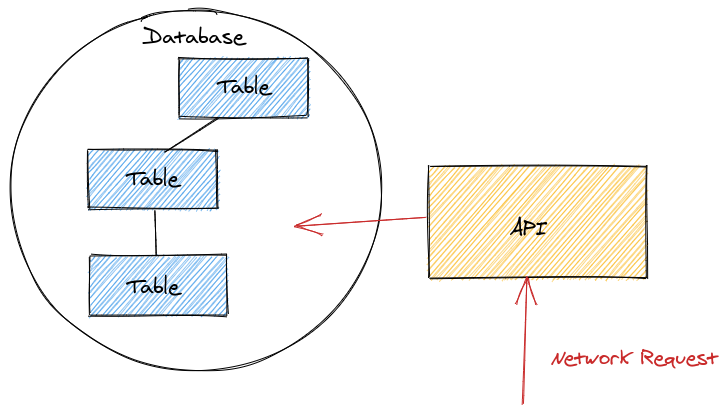
The tables in the database are related. I use ‘related’ loosely: there could be a foreign key from one table to another, maybe a shared identifier. To generalise, it is data that tends to be combined when queried.
A common anti-pattern I see is to break up related data:
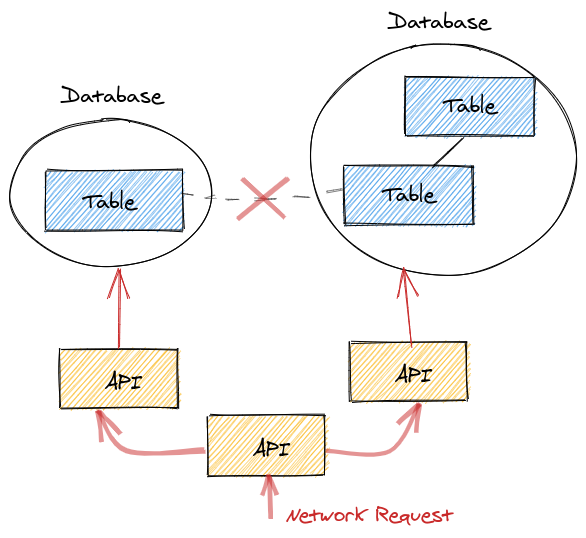
Notice how the relationship between two related tables has been pushed up from the database layer to the application layer.
This is often detrimental to reliability, performance, correctness, simplicity, flexibility and speed of development.
The Unreliable Network
Consider this pattern repeated further:
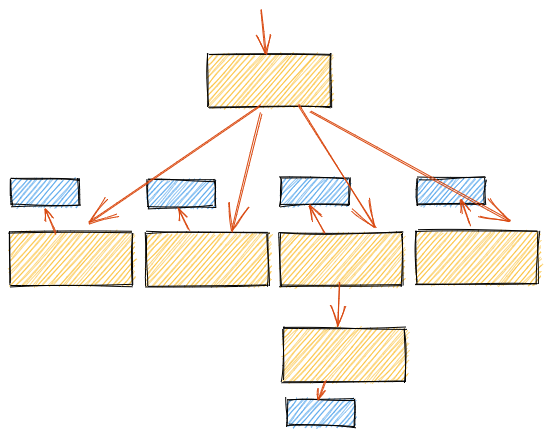
Here we see 11 network requests, 5 databases, and 6 servers, compared to the two network requests, single database, and server of the original.
If we consider each individual request to independently have a 99% chance of success, then the original top level request will have an accumulated 98% (0.992) success rate and this new example will have a 90% success rate (0.9911). This gets worse every time the pattern is extended.
See my article Microservices and Availability for a more detailed argument.
Loss of Functionality
This approach loses the functionality of the database, such as joins, filtering, ordering and aggregation. These must be re-implemented (often poorly) at the application layer.
For example, if two tables requires a simple join your API must fetch the results of the first table via the first API, find the relevant IDs, and request them from the second API. If you want to avoid an N+1 query the second API must now support some form of ‘multi-fetch’.
It could alternatively be implemented by denormalising the data, but that comes with its own costs and complexities.
The Interface Explosion Problem
Changes to the structure of the data can result in multiple changes to dependent APIs.
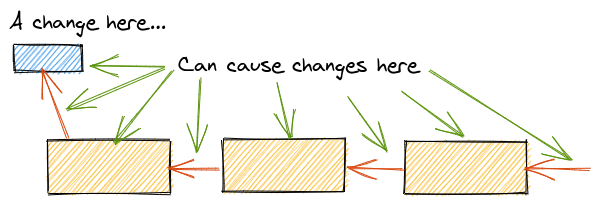
This can really slow down development and cause bugs! The fewer APIs between you and your data the better.
Incorrectness
Splitting data into multiple databases loses ACID transactions.
Short of introducing distributed transactions, any consistency between the tables has been lost and they cannot be updated atomically.
See my article Consistency is Consistently Undervalued for more thoughts on this.
Performance Crash
The ‘API’ is often a HTTP server with a JSON interface. At every step through the API stack, the TCP, HTTP and JSON serialisation performance costs must be paid.
Aggregations, filtering and joins performed at the application layer can also result in over-fetching from the database.